
Retrouvez dans cet article le retour d’expérience de notre Directeur Technique, Jean Humann, sur la meilleure méthode de versioning des données pour permettre une amélioration continue des transformations sans altérer la production.
Le data lakehouse prend le meilleur de deux mondes : d’une part la couche de stockage ouverte à faible coût du datalake, de l’autre les fonctions de gestion de données du data warehouse, des transactions ACID aux rollbacks. Toutefois, pour obtenir ces dernières dans un environnement tel que S3, une couche d’abstraction est indispensable à ce que les moteurs de calcul puissent comprendre requêter les groupes de fichiers de données brutes/les tables SQL.
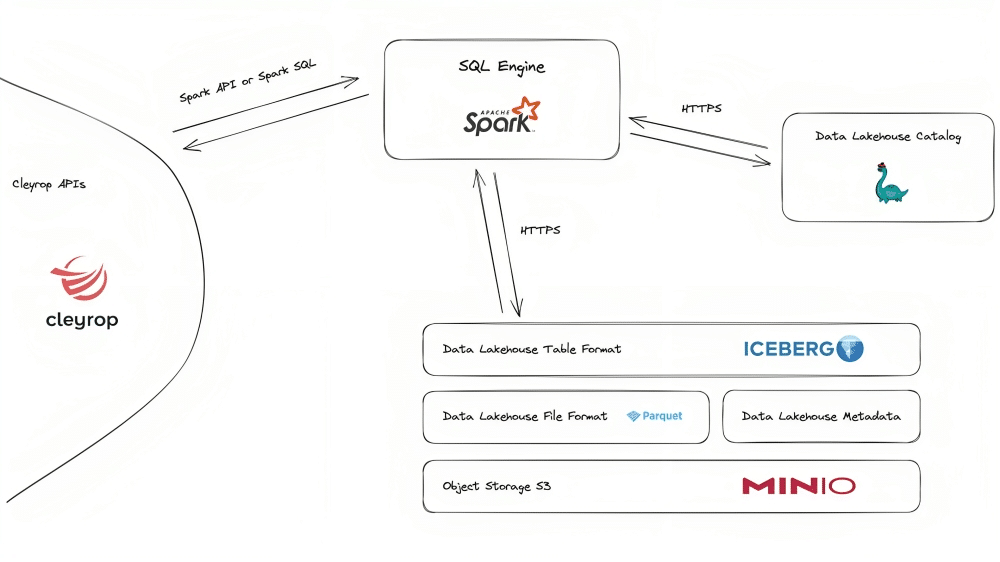
Chez Cleyrop, notre data lakehouse s’appuie sur un moteur SQL et sur un stockage objet pur, avec des données au format Apache Parquet. La couche d’abstraction est fournie par Apache Iceberg, un format de table open source né chez Netflix. Celui-ci vient écrire une couche de métadonnées qui aide les moteurs à comprendre le design et l’historique des tables, comme l’illustre le schéma ci-contre.
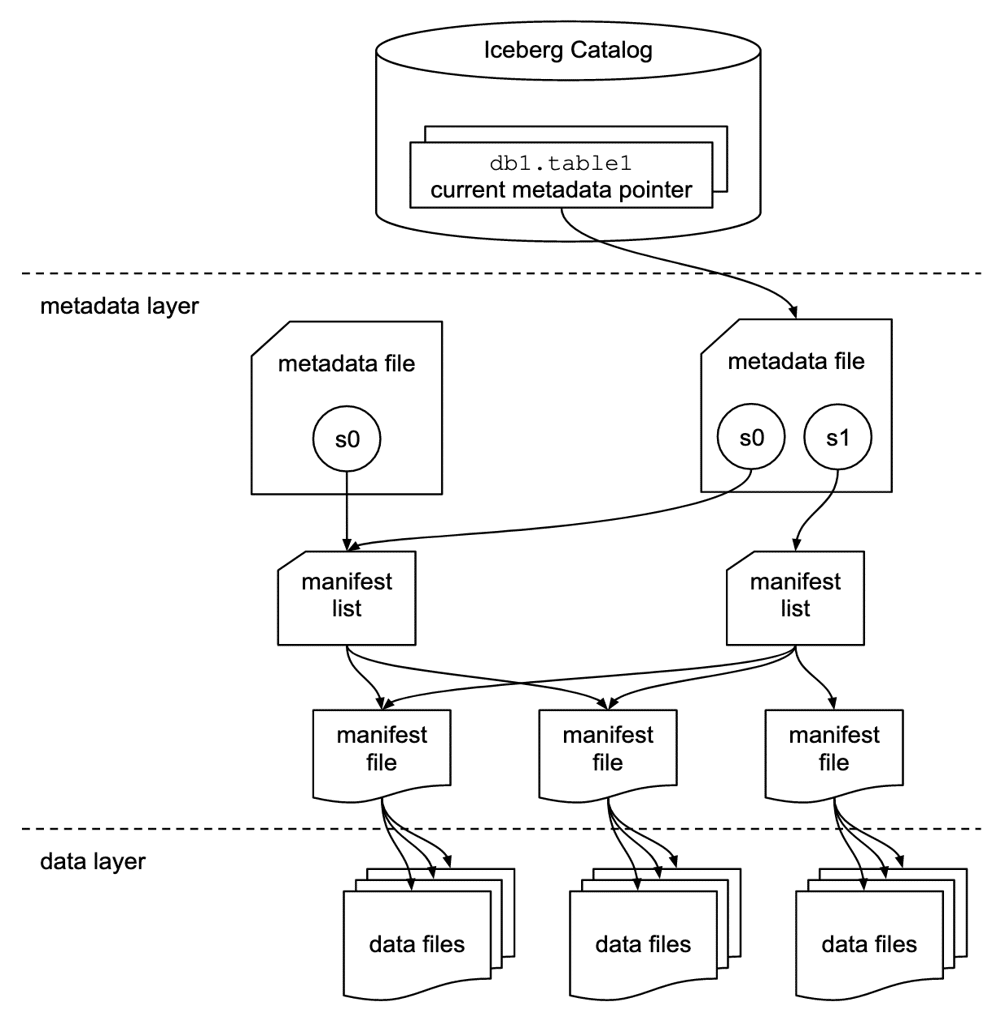
En d’autres termes, Iceberg permet de requêter en SQL simplement, de versionner la donnée, de lire et écrire en parallèle ou encore de pouvoir préserver les changements atomiques. Ce format de table s’adosse en outre à un catalogue de données, à l’instar de JDBC, Hive ou encore Nessie. Lorsque l’on requête une table via un moteur SQL, c’est d’abord ce catalogue que le moteur va appeler, pour ensuite retrouver les bonnes références des métadonnées Iceberg. Très schématiquement, le rôle d’un catalogue consiste à regrouper les tables et à les rendre détectables pour des outils tels que Spark ou Dremio.
Le versioning niveau catalogue avec Nessie
Mais là où la majorité des catalogues se cantonnent à cette découverte des tables, Nessie va plus loin. Il s’agit en effet de l’un des premiers catalogues open source offrant un catalogue transactionnel, conservant un historique de validation de l’ensemble des tables. Soit une sémantique « git-like » qui apporte des propriétés de versioning directement dans le data lakehouse, donc niveau catalogue des branches qui peuvent être étiquetées, ramifiées et fusionnées, avec des règles de contrôle d’accès rattachées non pas au moteur, mais au catalogue. Ainsi, les data engineers et autres data scientists peuvent venir itérer leurs processing de nettoyage de la donnée et effectuer des tests en toute sécurité, sans risquer d’impacter une branche en production.
Pour autant, ce versioning niveau catalogue n’est pas exempt de défauts. A commencer par une problématique de gestion des données, et plus particulièrement des fichiers de données derrière les tables. Ce souci se pose dans le cas fréquent où l’on veut ne plus stocker les données des tables mergées dans le main, ou supprimer des données inutiles. Iceberg est doté par défaut, par le biais de sa fonction PURGE, d’un garbage collector puissant. Il permet de supprimer l’ensemble des données liées aux tables dont on n’a plus besoin. Cette fonctionnalité est cependant désactivée dans Nessie, puisque le branching est fait au niveau du catalogue, et non des tables. Dès lors, le moteur ne trouvera plus une table fille si la table mère a été supprimée, et renverra à une erreur si l’on veut supprimer les données de cette table fille, pourtant toujours stockées dans Minio.
Il est possible d’opter pour des solutions de contournement, qui elles aussi vont rapidement montrer leurs limites. Chez Cleyrop, nous avons testé un premier mécanisme consistant à supprimer directement les données dans Minio, avec un job Kubernetes pour répercuter ces changements dans Nessie. Mais encore, une gestion fine des données, notamment des orphelins, reste complexe. En outre, cette méthode risque de mettre à mal le fonctionnement de Nessie avec Iceberg.
Une gestion fine des tables avec Iceberg 1.2.0
La solution est venue d’Iceberg lui-même. Dans ses dernières versions, à partir d’Iceberg 1.2.0, l’outil s’est doté de fonctionnalités de gestion des branches et des tags niveau table, ce qui permet de ne plus avoir à passer par un catalogue. Concrètement, dans Iceberg, chaque version d’une table, qualifiée de snapshot, peut être taguée, ramifiée ou mergée. Il est ainsi possible de créer une branche à partir d’un snapshot et de taguer cette branche pour y effectuer des modifications, tandis que le main demeure inchangé jusqu’au merge.
Cleyrop a fait le choix d’implémenter cette fonction et de modifier le catalogue de données, en passant de Nessie au catalogue REST, plus standard et poussé par l’équipe d’Iceberg. Celui-ci permet une meilleure connexion à d’autres applications et clients, appelable justement via API REST. On y retrouve la même sémantique git, le même système de commit observé côté Nessie, seules les commandes changent. Surtout, Iceberg 1.2.0 va plus loin que Nessie puisque le branching est effectué au niveau des tables, chacune ayant son propre git. Ainsi, il n’est plus nécessaire de chercher des stratégies de contournement pour supprimer les fichiers de données et les orphelins, puisque le versioning se fait côté table, et non plus au niveau du catalogue.
Conclusion, il n’y a pas de bon ou de mauvais versioning. Le branching par catalogue et le branching par table ont chacun leur intérêt. Le premier, lorsqu’il s’appuie sur Nessie, permet de gérer de la multi-transaction et le second, poussé par Iceberg en natif, d’avoir une gestion plus fine des données, notamment au niveau du garbage collector. Pourquoi ne pas avoir le meilleur des deux mondes en combinant les deux, vous demandez-vous ? Avoir à la fois une gestion niveau catalogue et la version table est techniquement faisable, mais s’avèrerait complexe côté utilisateur, du fait du double branching.
Références :
Spécifications techniques du catalogue REST : https://github.com/apache/iceberg/blob/master/open-api/rest-catalog-open-api.yaml
CLI Nessie : https://projectnessie.org/tools/cli/
Release Iceberg 1.2.0 : https://iceberg.apache.org/releases/#120-release