
The following article provides feedback from our Technical Director, Jean Humann, on the best method of versioning data to enable continuous improvement of transformations without altering production.
The data lakehouse takes the best of both worlds: on the one hand the low-cost, open storage layer of the datalake, on the other the data management functions of the data warehouse, from ACID transactions to rollbacks. However, to achieve the latter in an environment such as S3, a layer of abstraction is essential if compute engines are to understand how to query groups of raw data files/SQL tables.
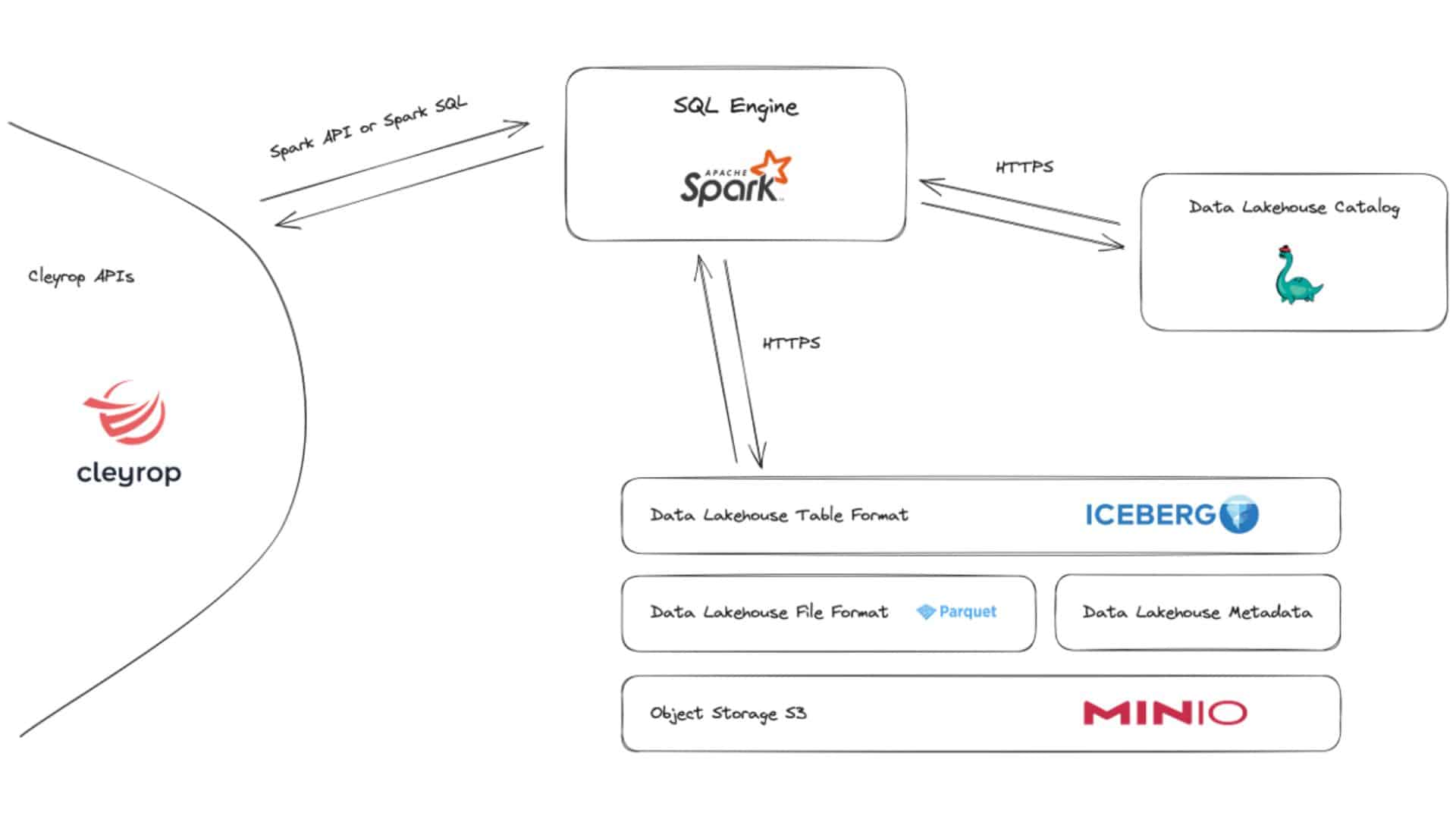
At Cleyrop, this data lakehouse is based on a SQL engine and pure S3 storage. Data is in Apache Parquet format. The abstraction layer is provided by Apache Iceberg, an open source table format developed by Netflix. It writes a layer of metadata that helps engines understand table design and history, as illustrated in the diagram opposite.
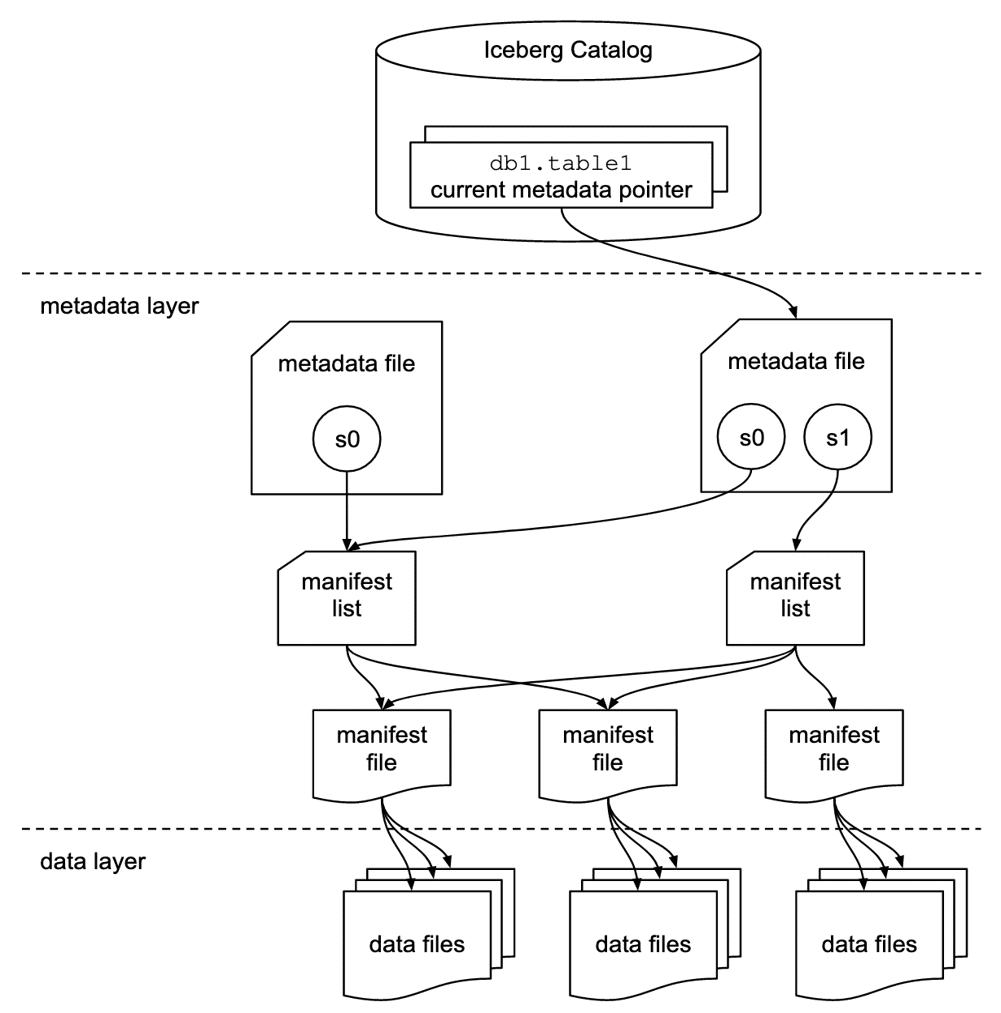
In other words, Iceberg allows for straightforward SQL querying, data versioning, parallel reading and writing, and the preservation of atomic changes. This table format is also associated with a data catalog, similar to JDBC, Hive, or Nessie. When querying a table through an SQL engine, the engine first calls this catalog to find the correct references to Iceberg metadata. In a simplified sense, the role of a catalog is to group tables and make them discoverable for tools like Spark or Dremio.
Catalog-Level Versioning with Nessie
However, where most catalogs limit themselves to table discovery, Nessie goes further. It is, in fact, one of the first open-source catalogs to offer a transactional catalog, preserving a history of validation for all tables. It provides a “git-like” semantics that brings versioning properties directly into the data lakehouse, at the catalog level. This includes the ability to label, branch, and merge branches with access control rules attached not to the engine but to the catalog. This allows data engineers and data scientists to safely iterate on data cleaning processes and conduct tests without risking impact on a production branch.
However, catalog-level versioning has its drawbacks. One issue arises with data management, particularly with the data files behind the tables. This becomes a concern when you want to stop storing merged table data in the main branch or delete unnecessary data. Iceberg includes a powerful garbage collector by default through its PURGE function, which can remove all data related to tables no longer needed. This functionality is disabled in Nessie since branching occurs at the catalog level, not the tables. As a result, the engine won’t find a child table if the parent table has been deleted, leading to an error if you attempt to delete the data from the child table, which is still stored in Minio.
Workaround solutions are possible, but they also have limitations. At Cleyrop, we tested one approach involving directly deleting data in Minio using a Kubernetes job to propagate these changes to Nessie. However, managing data, especially orphans, remains complex. Furthermore, this method may disrupt the functioning of Nessie with Iceberg.
Fine Table Management with Iceberg 1.2.0
The solution comes from Iceberg itself. In its latest versions, starting from Iceberg 1.2.0, the tool introduced branch and tag management features at the table level, eliminating the need for a catalog. In Iceberg, each version of a table, called a snapshot, can be tagged, branched, or merged. This allows you to create a branch from a snapshot, tag that branch for modifications, while the main branch remains unchanged until the merge.
Cleyrop chose to implement this feature and modify the data catalog, moving from Nessie to the REST catalog, which is more standard and supported by the Iceberg team. This REST catalog allows better integration with other applications and clients and can be accessed via the REST API. It maintains the same git semantics observed in Nessie, with only the commands differing. Importantly, Iceberg 1.2.0 goes further than Nessie, as branching is done at the table level, with each table having its own git. This eliminates the need for workaround strategies to delete data files and orphans, as versioning now happens at the table level, rather than the catalog level.
In conclusion, there is no one-size-fits-all versioning solution. Catalog-level branching and table-level branching each have their merits. The former, when based on Nessie, allows for multi-transaction management, while the latter, as pushed by Iceberg natively, offers finer data management, particularly with the garbage collector. You might wonder why not have the best of both worlds by combining the two. Technically, having both catalog-level and table-level versioning is possible but may prove complex for users due to the dual branching approach.
REST catalog technical specifications : https://github.com/apache/iceberg/blob/master/open-api/rest-catalog-open-api.yaml
CLI Nessie : https://projectnessie.org/tools/cli/
Version Iceberg 1.2.0 : https://iceberg.apache.org/releases/#120-release